- Published on
记一次 Java 服务导出报表 OOM 的排查过程
- Authors
- Name
- Foolgry
- @foolgryw
记一次 Java 服务导出报表 OOM 的排查过程
最近生产环境出了个 OOM 问题,场景虽然经典,但排查过程中还是有一些值得记录的细节。这里简单复盘一下整个排查流程。
1. 案发现场:生产环境 OOM
事情的起因是业务反馈 导出报表 功能挂了。 看了一下背景数据和环境配置:
- 数据量:涉及导出的数据大约在 50万 条左右。
- 运行环境:K8s + Docker + Spring Boot。
- 资源限制:Pod 限制 5G 内存,JVM 参数配置
-Xmx4096m(给堆内存分了 4G)。
按理说 4G 堆内存处理 50万数据,只要不是把所有对象一次性全加载到内存里,流式处理或者分页处理应该问题不大。但现实是服务直接崩了。
2. 场景复现与初步观测
为了不影响生产,我转到 UAT 环境 进行复现和观测。
- 测试数据:为了加快复现速度,用了 10万 条数据进行导出。
- 观测工具:使用 Arthas(或其他类似工具)的
dashboard面板实时监控。
观测现象: 在导出过程中,肉眼可见堆内存一直在疯涨。
- GC 情况:初期频繁触发 Young GC,随着导出进行,开始频繁 Full GC。
- 老年代(Old Gen):这是最致命的,Full GC 后内存并没有降下来,老年代占用率一直居高不下。
初步结论: 这明显不是简单的流量突发,而是代码层面存在内存泄漏或者持有大对象无法释放。
3. 保留证据:Heap Dump
既然确认是内存问题,下一步就是拿 Dump 文件分析了。
3.1 导出 Dump
使用 Arthas 的 heapdump 命令导出仅存活的对象(去除垃圾对象干扰):
heapdump --live /app/log/heap_dump.hprof
3.2 压缩传输(关键步骤)
这里有个经验之谈:生产导出的 Dump 文件通常巨大(接近 4G),直接下载非常慢,而且容易断。 建议在宿主机上先压缩再下载:
# 压缩后体积通常能缩小到原来的 1/10 左右
tar -zcvf heap_dump.tar.gz heap_dump.hprof
下载到本地后,解压准备分析。
4. 抽丝剥茧:本地分析
我直接把 Dump 文件拖进了 IntelliJ IDEA(现在 IDEA 自带的 Profiler 已经很好用了,或者用 MAT 也可以)。
分析思路:
- 打开 Profiler 视图。
- 按照 Retained Size(保留堆大小)倒序排列对象。
- 通过 Dominator Tree(支配树)查看究竟是谁占着内存不撒手。
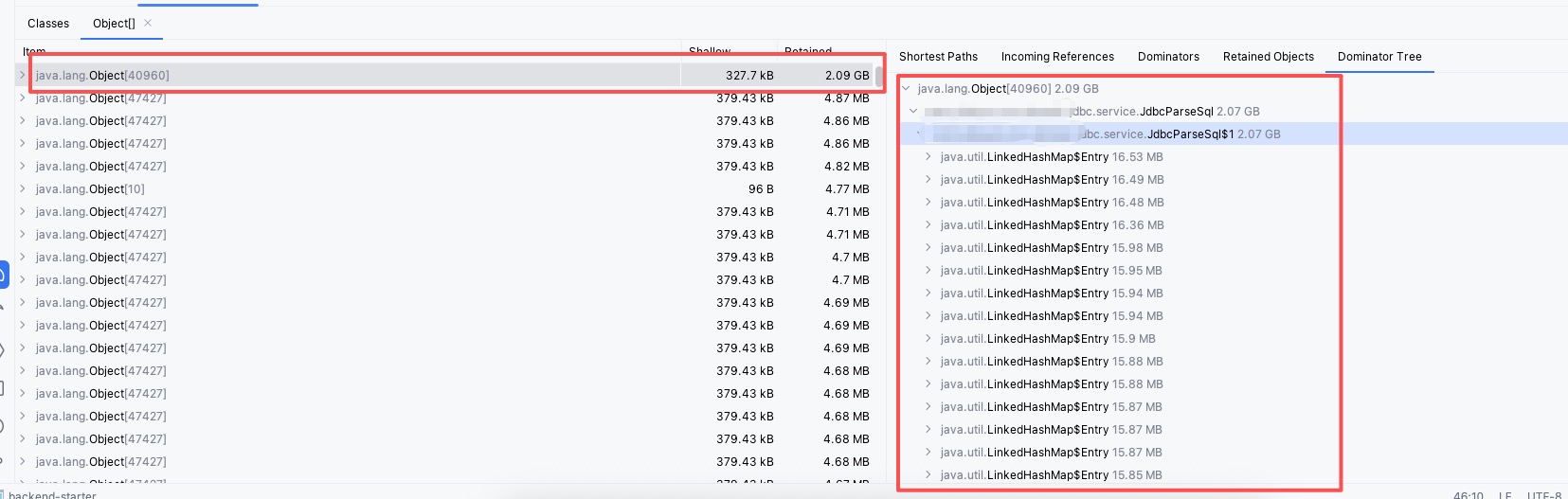
发现异常:
从图中可以清晰地看到:
- 内存中存在一个巨大的 SQL 解析缓存对象。
- 这个缓存的默认容量(Capacity)似乎是 256 个。
- 关键点来了:虽然只有 256 个坑位,但单条 SQL 解析后的对象体积大得离谱,平均一个就有十几兆(10MB+)。
5. 真相大白
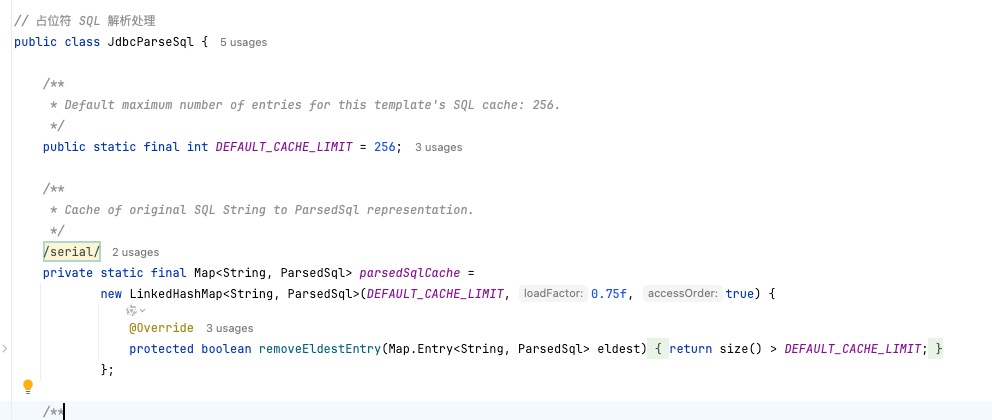 经过计算和代码确认: 由于导出涉及复杂的动态 SQL 拼接,系统使用的 ORM 框架对解析后的 SQL 进行了缓存。
经过计算和代码确认: 由于导出涉及复杂的动态 SQL 拼接,系统使用的 ORM 框架对解析后的 SQL 进行了缓存。
- 单个缓存对象 ≈ 15MB
- 缓存累积到 100 多个的时候:100 \times 15MB \approx 1.5GB
- 如果是默认存满 256 个:256 \times 15MB \approx 3.8GB
这就解释了为什么 4G 的堆内存会被瞬间吃光。看似不起眼的默认缓存配置,配合上超大的复杂 SQL 对象,直接撑爆了老年代。
总结: 这次排查其实并不复杂,关键在于在此类大数据量导出场景下,不要忽视框架层面的默认缓存策略。后续优化方案主要是针对该 SQL 解析缓存进行限制,过长的SQL不进入缓存列表。